

Antrea Egress: #
What is Egress when we talk about Kubernetes? Well if a pod wants to communicate to the outside world, outside the Kubernetes cluster it runs in, out of the worker node the pod resides on, this is egress traffic (definition “the action of going out of or leaving a place” and in network terminology means the direction is outward from itself).
Why does egress matter? Well, usually when the pods communicate out, they will use the IP address of the worker node they currently is deployed on. Thats means the actual pod IP is not the address you should be expecting when doing network inspection, tcpdump, firewall rules etc, it is the Kubernetes worker nodes IP addresses. What we call this network feature is NAT, Network Address Translation. All Kubernetes worker nodes will take the actual POD IP and translate it to its own IP before sending the traffic out of itself. And as we know, we don’t know where the pod will be deployed, and the pods can be many and will relocate so in certain environments it can be hard, not granular enough to create firewall rules in the perimeter firewall to allow or block traffic from a certain pod when needed when we only can use the IP addresses of the worker nodes.
Thats where Antrea Egress comes in. With Antrea Egress we have the option to dictate which specific IP address the POD can use when communication out by using an IP address that is not its POD IP address but a valid and allowed IP address in the network. You can read more on the Antrea Egress feature here
As the diagram below will illustrate, when pods communicate out, the will all get their POD IP addresses translated into the worker node’s IP address. And the firewall between worker node and the SQL server are only able to allow or block the IP address of the worker node. That means we potentially allow or block all pods coming from this node, or nodes if we allow the range of all the worker nodes.
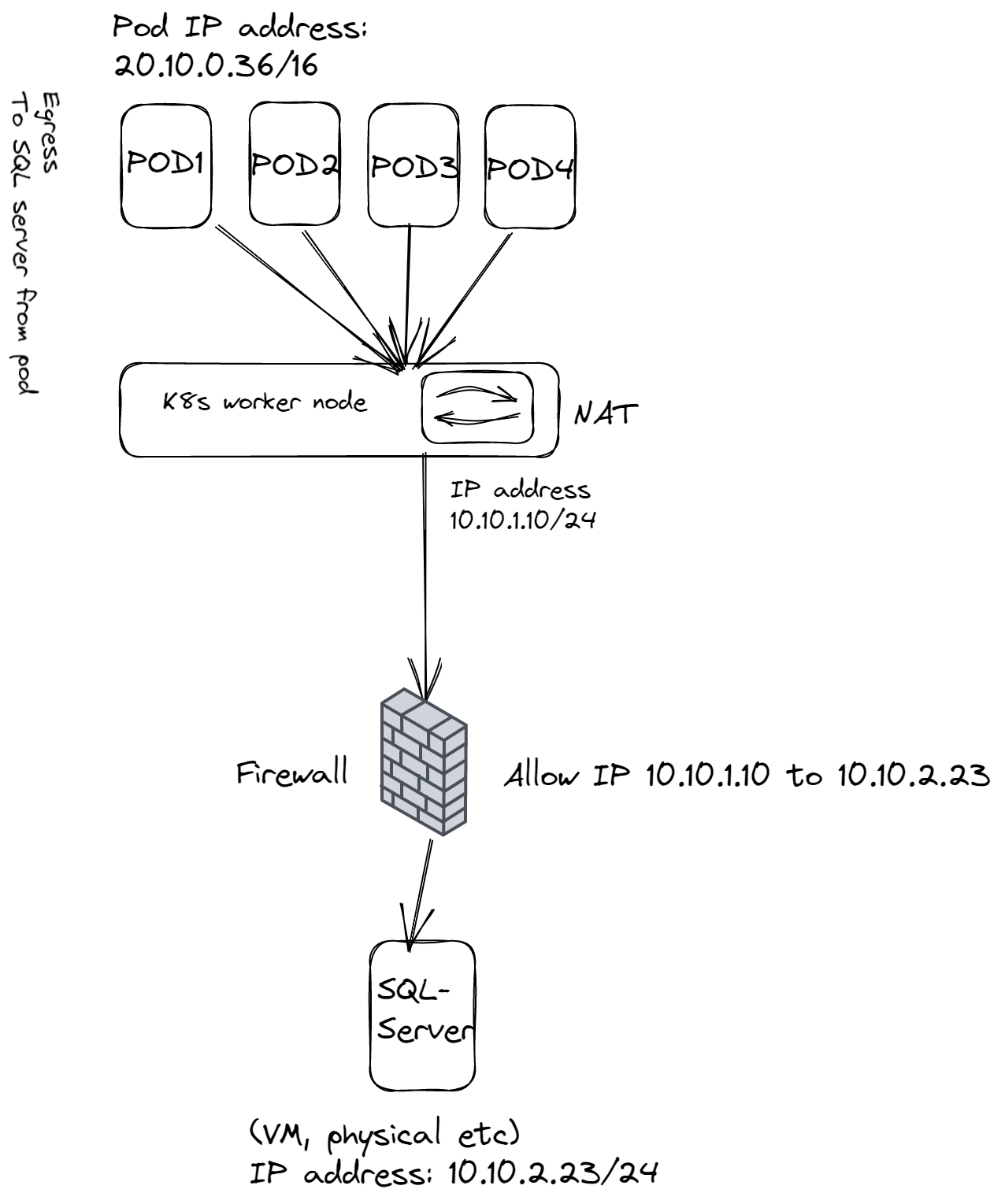
Ofcourse we can use Antrea Native Policies which I have written about here or VMware NSX with NCP, and VMware NSX with Antrea Integration to do fine grained security from source. But still there are environments we need to handle rules in perimeter firewalls.
So, this post will show how to enable Antrea Egress in vSphere 8 with Tanzu. With the current release of Antrea there is only support of using the same L2 network as worker nodes for the Antrea Egress IP-Pool.
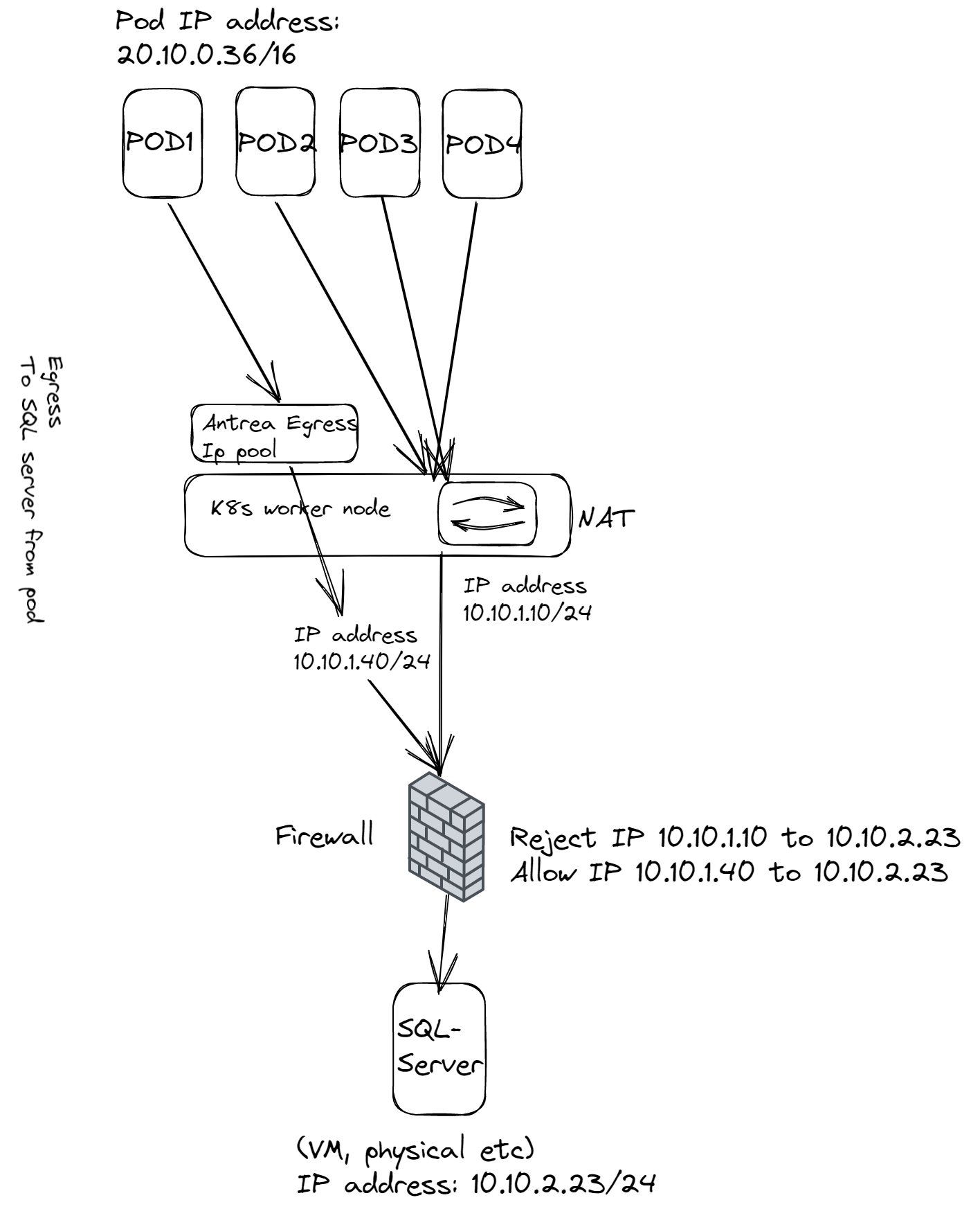
As we can see in the diagram above, Antrea Egress has been configured with an IP-Pool the pods can get if we apply Antrea Egress IPs for them to use. It will then take a free IP from the Egress IP Pool and which is within the same L2 subnet as the workers are configured on. This is very easy to do and achieve. No need to create static routes, Antrea takes care of the IP mapping. With this in place the firewall rule is now very strict, I can allow only the IP 10.10.1.40 (which is the IP the POD got from Antrea Egress Pool) and block the worker node ip address.
But…. I wanted to go a bit further and make use of L3 anyway for my Antrea Egress IP-Pool by utilizing BGP. Thats where the fun starts and this article is actually about. What I would like to achieve is that the IP address pool I configfure with Antrea Egress is something completely different from what the workers are using, not even the same L2 subnet but a completely different subnet. That means we need to involve some clever routing, and some configuration done on the worker nodes as its actually their IP addresses that becomes the gateway for our Antrea Egress subnets.
Something like this:
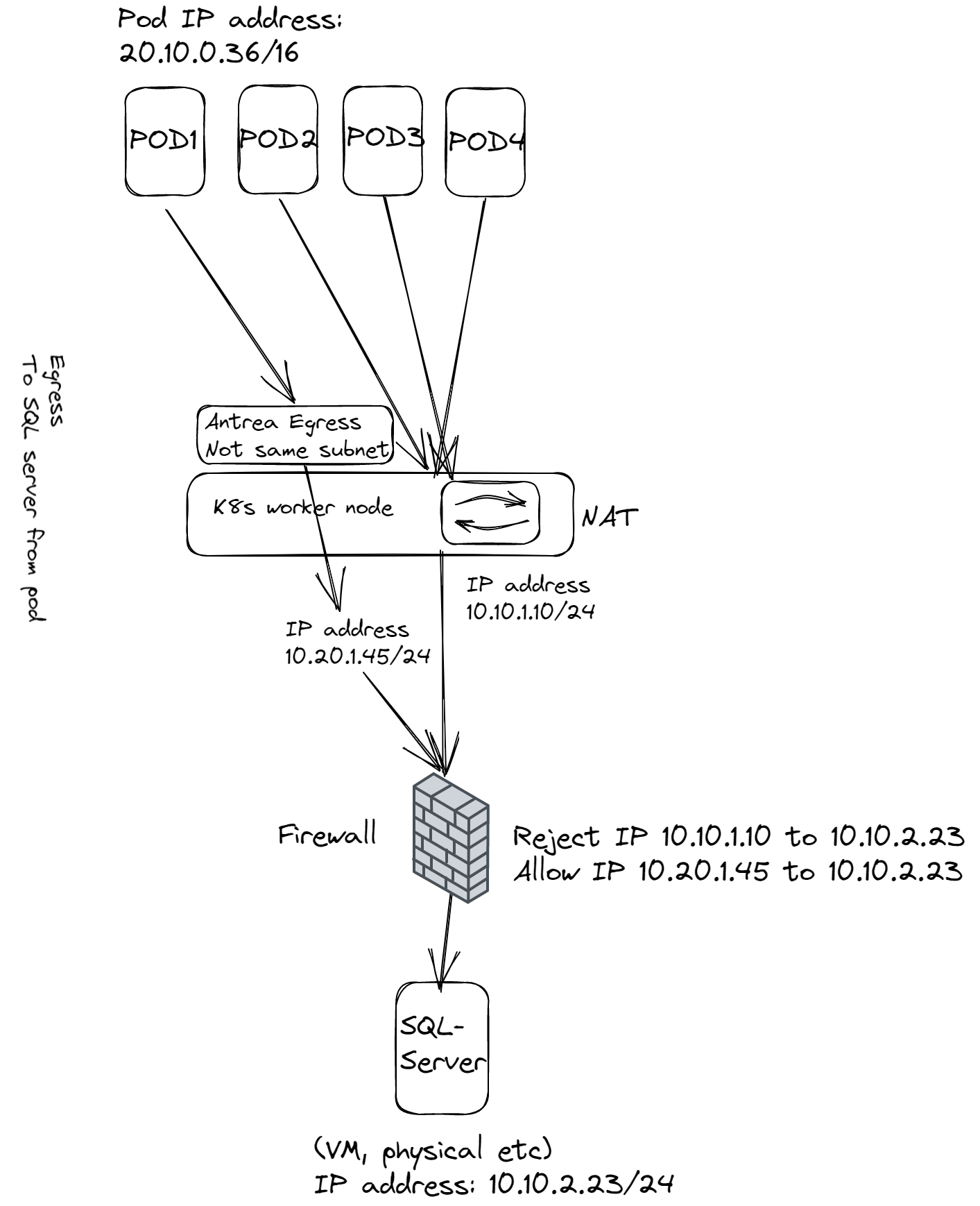
The diagram above shows a pod getting an IP address from the Egress pool which is something completely different from what subnet the worker node itself has. What Antrea does is creating a virtual interface on the worker node and assigns all the relevant ip addresses that are being used by Antrea Egress on that interface. They will use the default route on the worker node itself when going out, but the only component in the network that does know about this Egress subnet is the worker node itself, so it needs to tell this to his buddy routers out there. Either we create a static route on the router (could be the next hop of the worker node, the closest one, or some other hop in the infrastructure) or use BGP. Static route is more or less useless, too many ip addresses to update each time an egress ip is being applied, it could be on any worker node etc. So BGP is the way to go.
The Diagram below illustrates what happens if we dont tell our network routers where this network comes from and where it can be reached. It will egress out, but no one knows the way back.
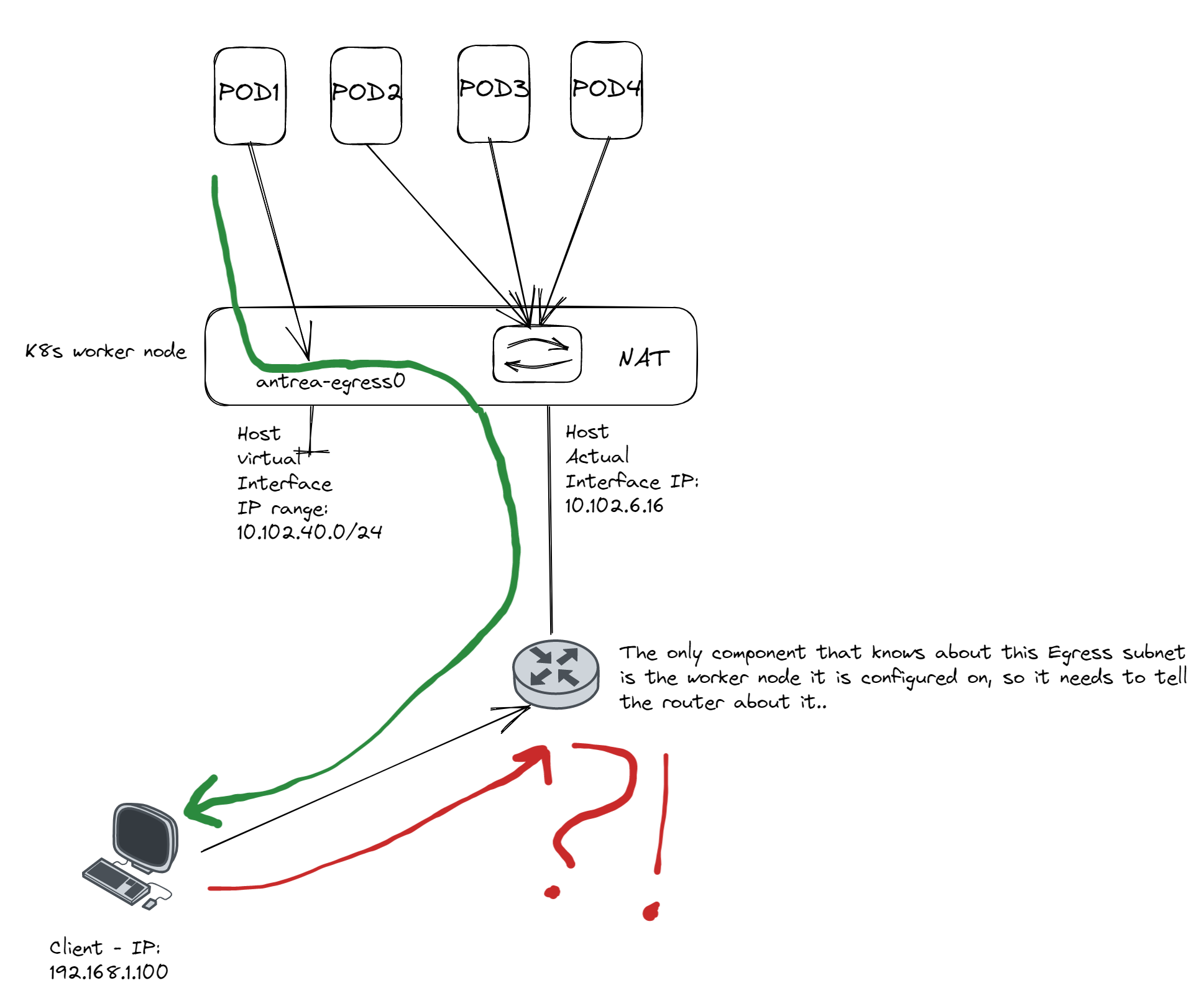
As soon as the routers are informed of the address to this IP address they will be more than happy to deliver it for us, thats their job. Imagine being a postman delivering a packet somewhere in a country without any direction, address etc to narrow down his search field. In the scenario above the return traffic will most likely be sent out via a default route to the Internet and never to be seen again 😄
So after we have been so kind to update with the exact delivery address below, we will get our mail again.
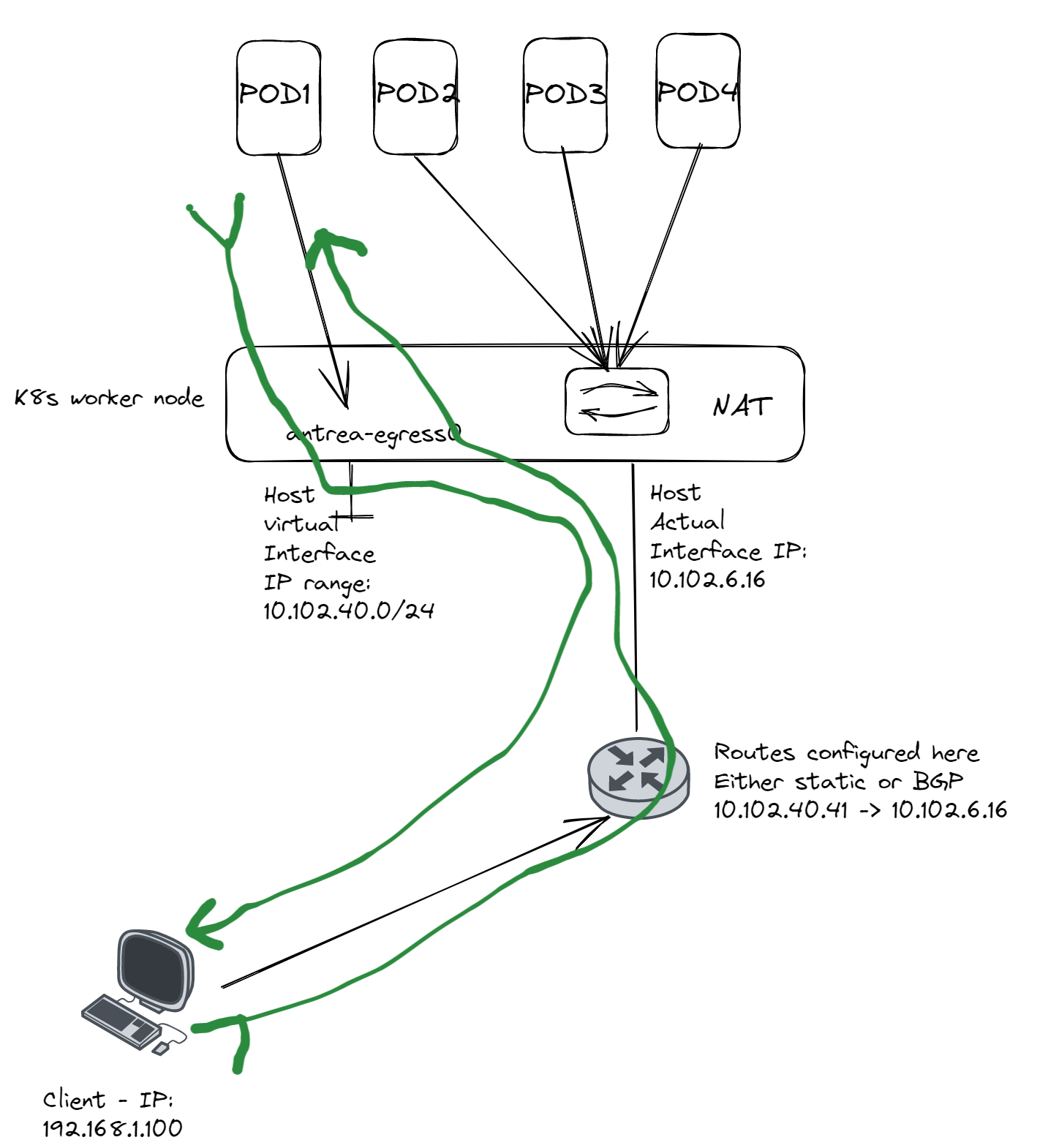
Enough explanation already, get to the actual config of this.
Configure Antrea Egress in TKC (vSphere 8) #
Deploy your TKC cluster, it must be Ubuntu os for this to work:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: wdc-2-tkc-cluster-1 # give your tkc cluster a name
namespace: wdc-2-ns-1 # remember to put it in your defined vSphere Namespace
spec:
clusterNetwork:
services:
cidrBlocks: ["20.10.0.0/16"]
pods:
cidrBlocks: ["20.20.0.0/16"]
serviceDomain: "cluster.local"
topology:
class: tanzukubernetescluster
version: v1.23.8---vmware.2-tkg.2-zshippable
controlPlane:
replicas: 1
metadata:
annotations:
run.tanzu.vmware.com/resolve-os-image: os-name=ubuntu
workers:
machineDeployments:
- class: node-pool
name: node-pool-01
replicas: 3
metadata:
annotations:
run.tanzu.vmware.com/resolve-os-image: os-name=ubuntu
variables:
- name: vmClass
value: best-effort-medium
- name: storageClass
value: vsan-default-storage-policy
Apply the correct Antrea configs, enable the Egress feature:
apiVersion: cni.tanzu.vmware.com/v1alpha1
kind: AntreaConfig
metadata:
name: wdc-2-tkc-cluster-1-antrea-package
namespace: wdc-2-ns-1
spec:
antrea:
config:
featureGates:
AntreaProxy: true
EndpointSlice: false
AntreaPolicy: true
FlowExporter: false
Egress: true #This needs to be enabled
NodePortLocal: true
AntreaTraceflow: true
NetworkPolicyStats: true
Log in to your newly created TKC cluster:
kubectl-vsphere login --server=10.102.7.11 --insecure-skip-tls-verify --vsphere-username=andreasm@cpod-nsxam-wdc.az-wdc.cloud-garage.net --tanzu-kubernetes-cluster-name tkc-cluster-1 --tanzu-kubernetes-cluster-namespace ns-1
Delete the Antrea Controller and Agent pods. Now that we have done the initial config of our TKC cluster its time to test Antrea Egress within same subnet as worker nodes just to verify that it works.
From now on you should stay in the context of your newly created TKC cluster.
Verify Antrea Egress works with L2 #
To be able to use Antrea Egress we need to first start with an IP-Pool definition. So I create my definition like this:
apiVersion: crd.antrea.io/v1alpha2
kind: ExternalIPPool
metadata:
name: antrea-ippool-l2 #just a name of this specific pool
spec:
ipRanges:
- start: 10.102.6.40 # make sure not to use already used ips
end: 10.102.6.50 # should not overlap with worker nodes
# - cidr: 10.101.112.0/32 # or you can define a whole range with cidr /32, /27 etc
nodeSelector: {} # you can remove the brackets and define which nodes you want below by using labels
# matchLabels:
# egress-l2: antrea-egress-l2
Apply your yaml definition above:
andreasm@linuxvm01:~/antrea/egress$ k apply -f ippool.wdc2.tkc.cluster-1.yaml
externalippool.crd.antrea.io/antrea-ippool-l2 created
Then we need to define the actual Egress itself. What we do with this config is selecting which pod that should get an Egress ip, from wich Antrea Egress IP pool (we can have several). So here is my example:
apiVersion: crd.antrea.io/v1alpha2
kind: Egress
metadata:
name: antrea-egress-l2 #just a name of this specific Egress config
spec:
appliedTo:
podSelector:
matchLabels:
app: ubuntu-20-04 ###Which pods should get Egress IPs
externalIPPool: antrea-ippool-l2 ###The IP pool I defined above.
Before I apply it I will just make sure that I have a pod running the these labels, if not I will deploy it and then apply the Egress. So before I apply it I will show pinging from my pod to my jumpbox VM to identify which IP it is using before applying the Egress. And the apply the Egress and see if IP changes from the POD.
My ubuntu pod is up and running, I have entered the shell on it and initiates a ping from my pod to my jumpbox VM:
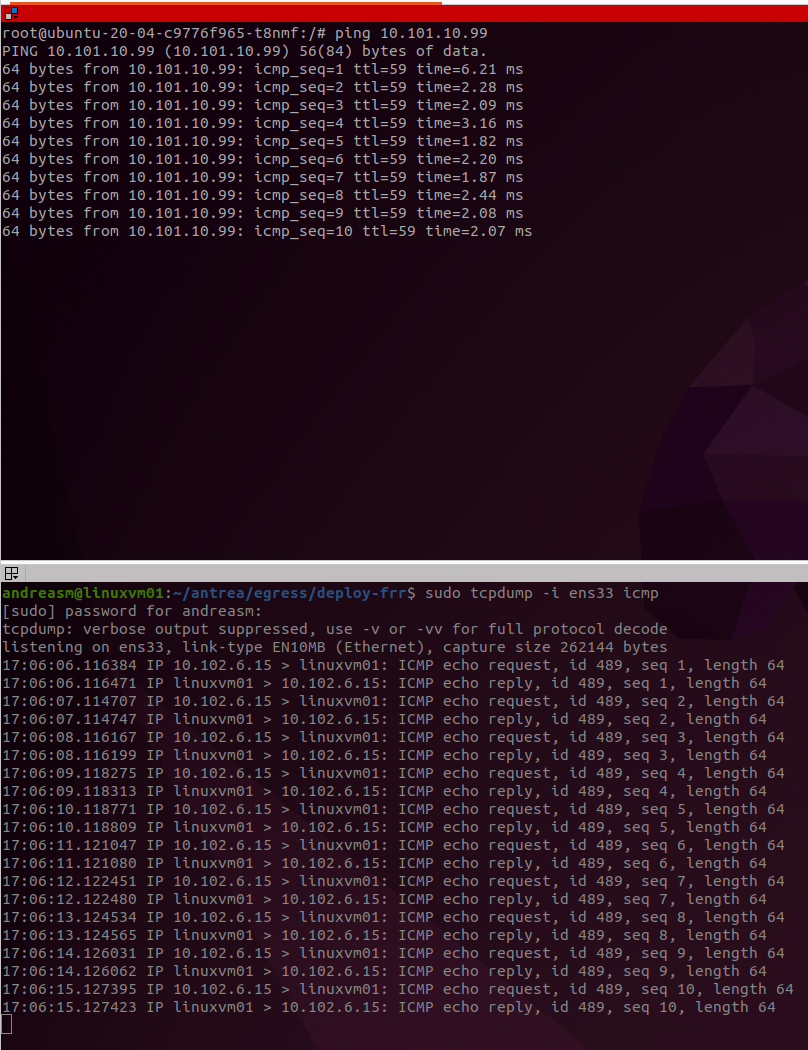
So here I can see the POD identifies itself with IP 10.102.6.15. Well which worker is that?:
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get pods -n prod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ubuntu-20-04-c9776f965-t8nmf 1/1 Running 0 20h 20.40.1.2 wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds <none> <none>
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-qn52t Ready <none> 20h v1.23.8+vmware.2 10.102.6.16 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-wmj7z Ready <none> 20h v1.23.8+vmware.2 10.102.6.17 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds Ready <none> 20h v1.23.8+vmware.2 10.102.6.15 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-xrj44-qq24c Ready control-plane,master 20h v1.23.8+vmware.2 10.102.6.14 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
That is this worker: wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds.
So far so good. Now let me apply the Egress on this POD.
andreasm@linuxvm01:~/antrea/egress$ k apply -f antrea.egress.l2.yaml
egress.crd.antrea.io/antrea-egress-l2 created
Now how does the ping look like?
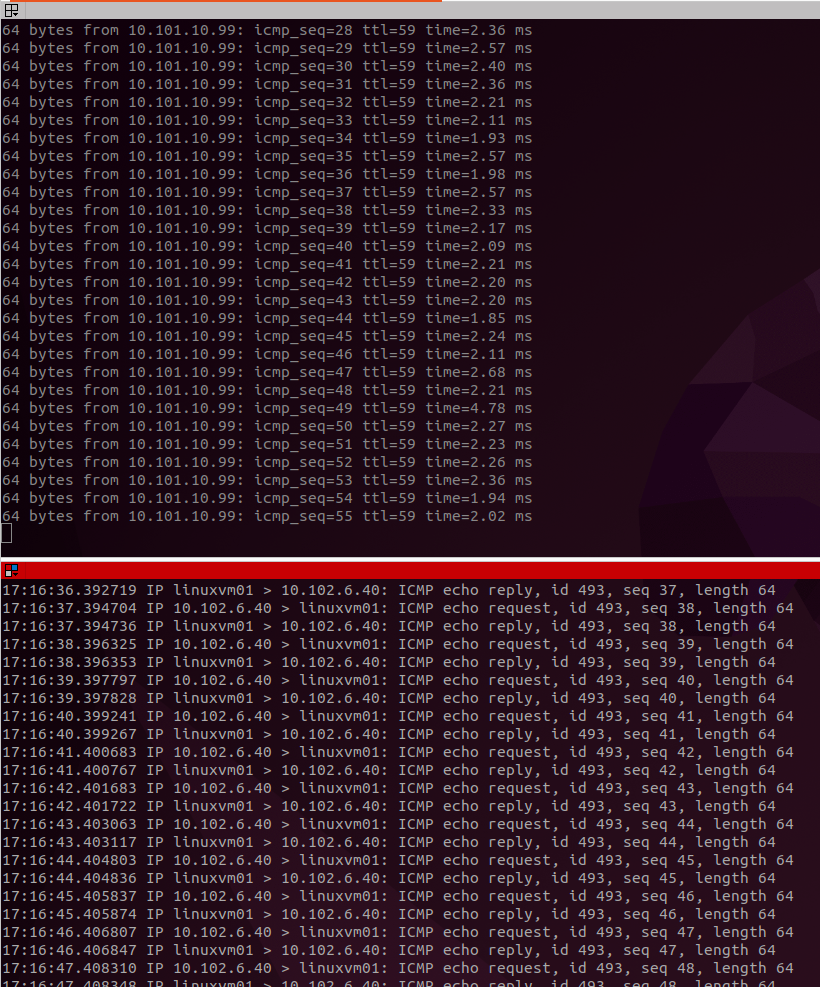
This was as expected was it not? The POD now identifies itself with the IP 10.102.6.40 which happens to be the first IP in the range defined in the pool. Well, this is cool. Now we now that Antrea Egress works. But as mentioned, I want this to be done with a different subnet than the worker nodes. Se lets see have we can do that as “seemless” as possible, as we dont want to SSH into the worker nodes and do a bunch of manual installation, configuration and so on. No, we use Kubernetes for our needs here also.
Configure FRR on worker nodes #
What I want to achieve is to deploy FRR here on my worker nodes unattended to enable BGP pr worker node to my upstream BGP router (remember, to inform about the Egress network no one knows about). The TKC workers are managed appliances, they can be deleted, scaled up and down (more workers, fewer workers.) And Deploying something manual on them are just waste of time. So we need something that deploy FRR automatically on the worker nodes.
FRR is easy to deploy and configure, and it is included in the Ubuntu default repo (one reason I wanted to use Ubuntu as worker os). FRR is a very good routing protocol suite in Linux and is deployed easy on Ubuntu with “apt install frr”. FRR can be configured to use BGP which is the routing protocol I want to use. FRR needs two config files, daemons and frr.conf. frr.conf is individual pr node (specific IP addresses) so we need to take that into consideration also. So how can I deploy FRR on the worker nodes with their individal configuration files to automatically establish a BGP neighbourship with my Upstream router, and without logging into the actual worker nodes themselves?
Below diagram just illustrating a tkc worker node with FRR installed and BGP configured:
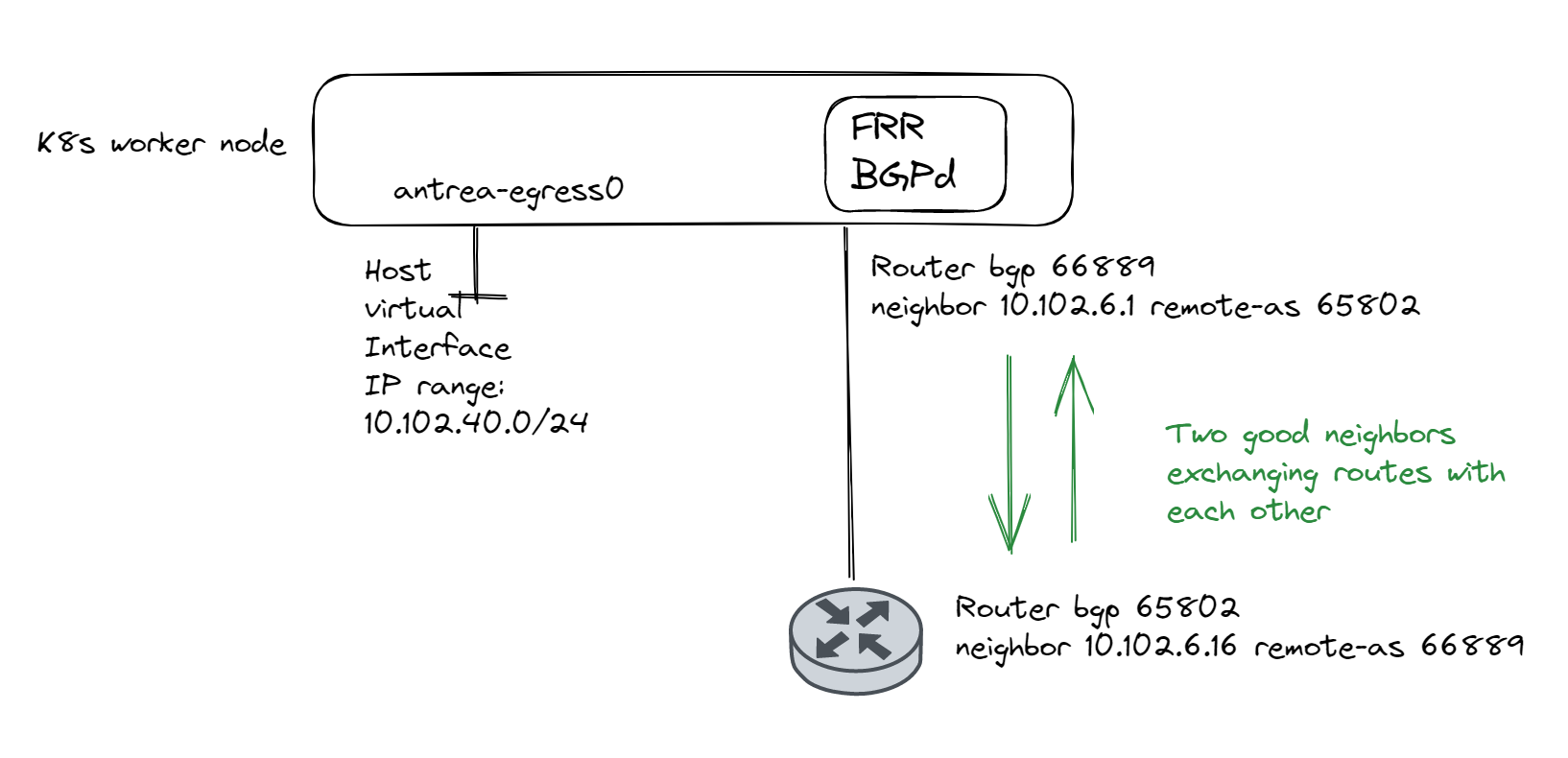
Kubernetes and Daemonset. #
I have created three Daemonset definition files, one for the actual deployment of FRR on all the nodes:
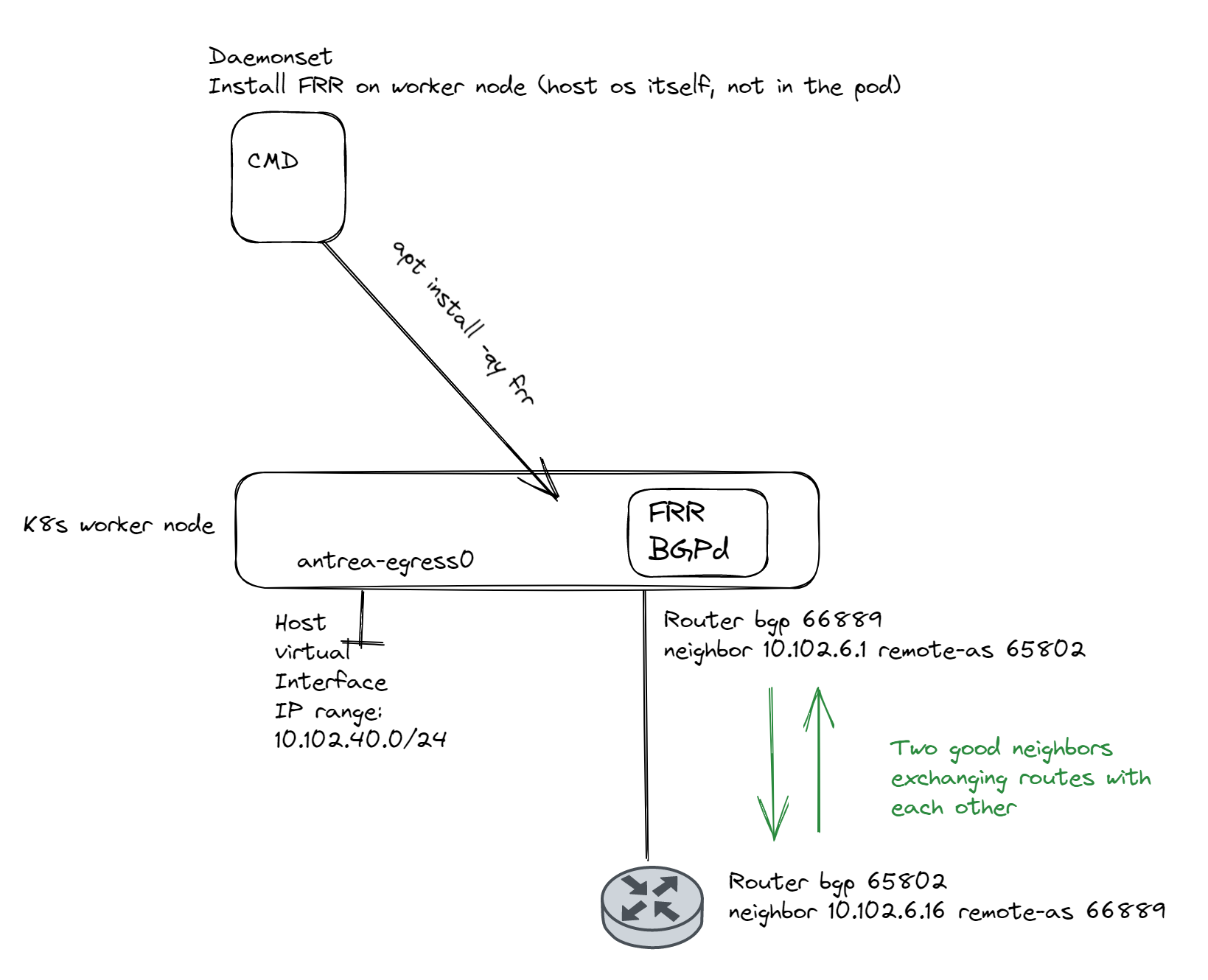
Then I have created on Daemonset definition to copy the frr.conf and daemons file for the specific worker nodes and the last definition file is used to uninistall everything on the worker nodes themselves (apt purge frr) if needed.
Lets start by just deploy FRR on the workers themselves.
Here is the defintion for that:
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: node-custom-setup
labels:
k8s-app: node-custom-setup
annotations:
command: &cmd apt-get update -qy && apt-get install -qy frr
spec:
selector:
matchLabels:
k8s-app: node-custom-setup
template:
metadata:
labels:
k8s-app: node-custom-setup
spec:
hostNetwork: true
initContainers:
- name: init-node
command:
- nsenter
- --mount=/proc/1/ns/mnt
- --
- sh
- -c
- *cmd
image: alpine:3.7
securityContext:
privileged: true
hostPID: true
containers:
- name: wait
image: pause:3.1
hostPID: true
hostNetwork: true
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
updateStrategy:
type: RollingUpdate
Before I apply the above definiton I have logged into one of my TKC worker node and just wants to show that there is no FRR installed:
sh-5.0# cd /etc/frr
sh: cd: /etc/frr: No such file or directory
sh-5.0# systemctl status frr
Unit frr.service could not be found.
sh-5.0# hostname
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds
sh-5.0#
Now apply:
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k apply -f deploy-frr.yaml
daemonset.apps/node-custom-setup configured
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get pods -n kube-system
NAME READY STATUS RESTARTS AGE
antrea-agent-4jrks 2/2 Running 0 20h
antrea-agent-4khkr 2/2 Running 0 20h
antrea-agent-4wxb5 2/2 Running 0 20h
antrea-agent-ccglp 2/2 Running 0 20h
antrea-controller-56d86d6b9b-hvrtc 1/1 Running 0 20h
coredns-7d8f74b498-j5sjt 1/1 Running 0 21h
coredns-7d8f74b498-mgqrm 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-qn52t 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-wmj7z 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
etcd-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-apiserver-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-controller-manager-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-proxy-44qxn 1/1 Running 0 21h
kube-proxy-4x72n 1/1 Running 0 21h
kube-proxy-shhxb 1/1 Running 0 21h
kube-proxy-zxhdb 1/1 Running 0 21h
kube-scheduler-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
metrics-server-6777988975-cxnpv 1/1 Running 0 21h
node-custom-setup-5rlkr 1/1 Running 0 34s #There they are
node-custom-setup-7gf2v 1/1 Running 0 62m #There they are
node-custom-setup-b4j4l 1/1 Running 0 62m #There they are
node-custom-setup-wjpgz 0/1 Init:0/1 0 1s #There they are
Now what has happened on the TKC worker nodes itself:
sh-5.0# cd /etc/frr/
sh-5.0# pwd
/etc/frr
sh-5.0# ls
daemons frr.conf support_bundle_commands.conf vtysh.conf
sh-5.0# systemctl status frr
● frr.service - FRRouting
Loaded: loaded (/lib/systemd/system/frr.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2023-02-20 17:53:33 UTC; 1min 36s ago
Wow that looks good. But the frr.conf is more or less empty so it doesnt do anything right now.
A note on FRR config on the worker nodes #
Before jumping into this section I would like to elaborate a bit around the frr.conf files being copied. If you are expecting that all worker nodes will be on same BGP AS number and your next-hop BGP neighbors are the same ones and in the same L2 as your worker node (illustrated above) you could probably go with the same config for all worker nodes. Then you can edit the same definition used for the FRR deployment to also copy and install the config in the same operation. The steps I do below describes individual config pr worker node. If you need different BGP AS numbers, multi-hop (next-hop is several hops away), individual update-source interfaces is configured then you need individual frr.config pr node.
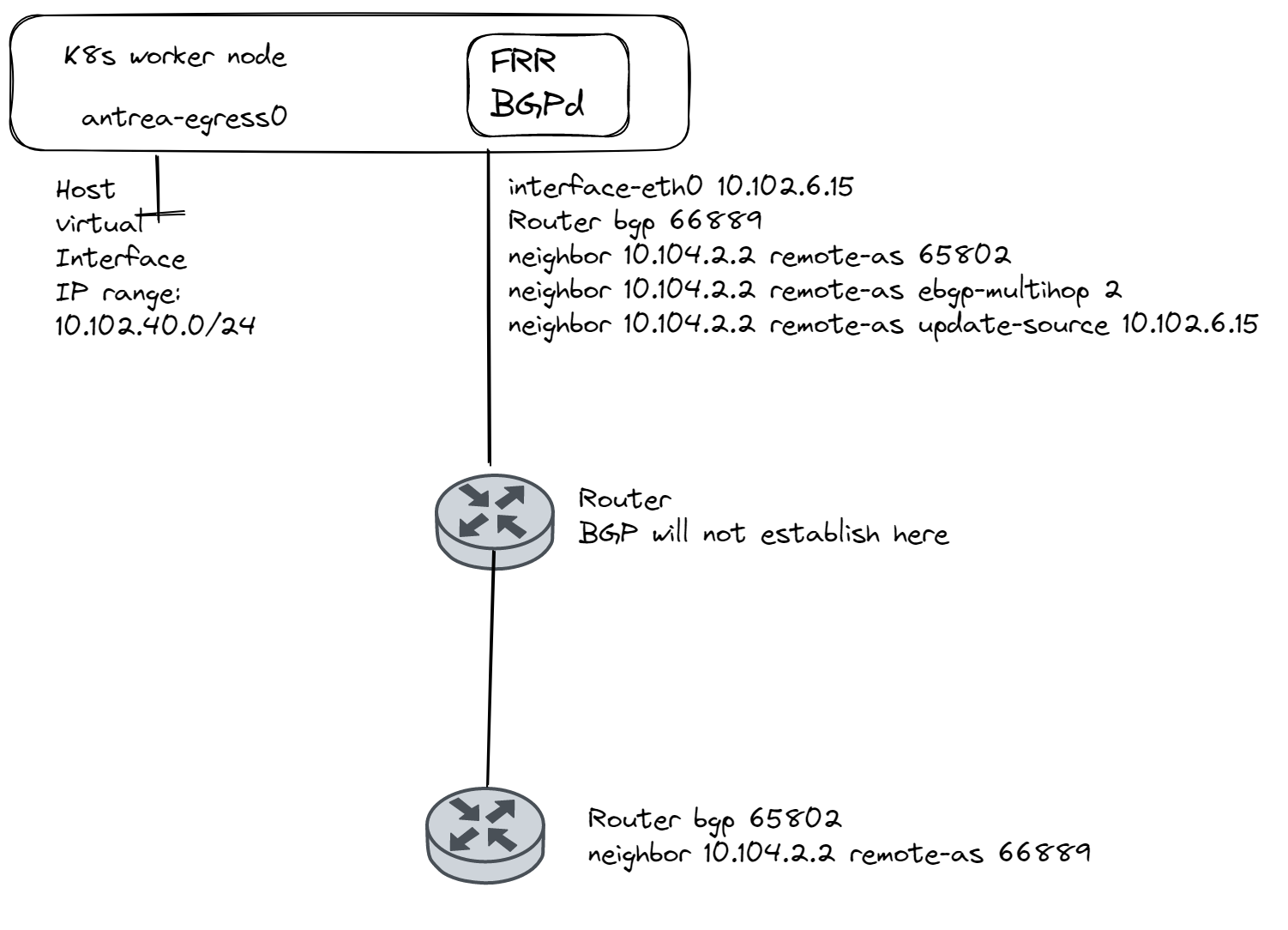
Individual FRR config on the worker nodes #
I need to “inject” the correct config for each worker node. So I label each and one with their unique label like this: (I map the names node1->lowest-ip)
I have already configured my upstream bgp router to accept my workers as soon as they are configured and ready. This is how this looks.
router bgp 65802
bgp router-id 172.20.0.102
redistribute connected
neighbor 10.102.6.15 remote-as 66889
neighbor 10.102.6.16 remote-as 66889
neighbor 10.102.6.17 remote-as 66889
neighbor 172.20.0.1 remote-as 65700
!
address-family ipv6
exit-address-family
exit
cpodrouter-nsxam-wdc-02# show ip bgp summary
BGP router identifier 172.20.0.102, local AS number 65802
RIB entries 147, using 16 KiB of memory
Peers 4, using 36 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.102.6.15 4 66889 1191 1197 0 0 0 never Active # Node1 not Established yet
10.102.6.16 4 66889 0 0 0 0 0 never Active # Node2 not Established yet
10.102.6.17 4 66889 1201 1197 0 0 0 never Active # Node3 not Established yet
172.20.0.1 4 65700 19228 19172 0 0 0 01w4d09h 65
To verify again, this is the current output of frr.conf on node1:
sh-5.0# cat frr.conf
# default to using syslog. /etc/rsyslog.d/45-frr.conf places the log
# in /var/log/frr/frr.log
log syslog informational
sh-5.0#
This is the definition I use to copy the daemons and frr.conf for the individual worker nodes:
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: node-frr-config
labels:
k8s-app: node-frr-config
annotations:
command: &cmd cp /tmp/wdc-2.node1.frr.conf /etc/frr/frr.conf && cp /tmp/daemons /etc/frr && systemctl restart frr
spec:
selector:
matchLabels:
k8s-app: node-frr-config
template:
metadata:
labels:
k8s-app: node-frr-config
spec:
nodeSelector:
nodelabel: wdc2-node1 #Here is my specific node selection done
hostNetwork: true
initContainers:
- name: copy-file
image: busybox
command: ['sh', '-c', 'cp /var/nfs/wdc-2.node1.frr.conf /var/nfs/daemons /data']
volumeMounts:
- name: nfs-vol
mountPath: /var/nfs # The mountpoint inside the container
- name: node-vol
mountPath: /data
- name: init-node
command:
- nsenter
- --mount=/proc/1/ns/mnt
- --
- sh
- -c
- *cmd
image: alpine:3.7
securityContext:
privileged: true
hostPID: true
containers:
- name: wait
image: pause:3.1
hostPID: true
hostNetwork: true
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
volumes:
- name: nfs-vol
nfs:
server: 10.101.10.99
path: /home/andreasm/antrea/egress/FRR/nfs
- name: node-vol
hostPath:
path: /tmp
type: Directory
updateStrategy:
type: RollingUpdate
Notice this:
nodeSelector:
nodelabel: wdc2-node1
This is used to select the correct node after I have labeled them like this:
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-qn52t Ready <none> 21h v1.23.8+vmware.2 10.102.6.16 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-wmj7z Ready <none> 21h v1.23.8+vmware.2 10.102.6.17 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds Ready <none> 21h v1.23.8+vmware.2 10.102.6.15 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-xrj44-qq24c Ready control-plane,master 21h v1.23.8+vmware.2 10.102.6.14 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k label node wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds nodelabel=wdc2-node1
node/wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds labeled
So its just about time to apply the configs pr node:
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k apply -f wdc2.frr.node1.config.yaml
daemonset.apps/node-custom-setup configured
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get pods -n kube-system
NAME READY STATUS RESTARTS AGE
antrea-agent-4jrks 2/2 Running 0 21h
antrea-agent-4khkr 2/2 Running 0 21h
antrea-agent-4wxb5 2/2 Running 0 21h
antrea-agent-ccglp 2/2 Running 0 21h
antrea-controller-56d86d6b9b-hvrtc 1/1 Running 0 21h
coredns-7d8f74b498-j5sjt 1/1 Running 0 21h
coredns-7d8f74b498-mgqrm 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-qn52t 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-wmj7z 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds 1/1 Running 0 21h
docker-registry-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
etcd-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-apiserver-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-controller-manager-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
kube-proxy-44qxn 1/1 Running 0 21h
kube-proxy-4x72n 1/1 Running 0 21h
kube-proxy-shhxb 1/1 Running 0 21h
kube-proxy-zxhdb 1/1 Running 0 21h
kube-scheduler-wdc-2-tkc-cluster-1-xrj44-qq24c 1/1 Running 0 21h
metrics-server-6777988975-cxnpv 1/1 Running 0 21h
node-custom-setup-w4mg5 0/1 Init:0/2 0 4s
Now what does my upstream router say:
cpodrouter-nsxam-wdc-02# show ip bgp summary
BGP router identifier 172.20.0.102, local AS number 65802
RIB entries 149, using 16 KiB of memory
Peers 4, using 36 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.102.6.15 4 66889 1202 1209 0 0 0 00:00:55 2 #Hey I am a happy neighbour
10.102.6.16 4 66889 0 0 0 0 0 never Active
10.102.6.17 4 66889 1201 1197 0 0 0 never Active
172.20.0.1 4 65700 19249 19194 0 0 0 01w4d10h 65
Total number of neighbors 4
Total num. Established sessions 2
Total num. of routes received 67
Then I just need to deploy on the other two workers.
My upstream bgp router is very happy to have new established neighbours:
cpodrouter-nsxam-wdc-02# show ip bgp summary
BGP router identifier 172.20.0.102, local AS number 65802
RIB entries 153, using 17 KiB of memory
Peers 4, using 36 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.102.6.15 4 66889 1221 1232 0 0 0 00:01:01 2
10.102.6.16 4 66889 11 16 0 0 0 00:00:36 2
10.102.6.17 4 66889 1225 1227 0 0 0 00:00:09 2
172.20.0.1 4 65700 19254 19205 0 0 0 01w4d10h 65
Total number of neighbors 4
Antrea IP Pool outside subnet of worker nodes #
Lets apply an IP pool which resides outside worker nodes subnet and apply Egress on my test pod again.
Here is the IP pool config:
apiVersion: crd.antrea.io/v1alpha2
kind: ExternalIPPool
metadata:
name: antrea-ippool-l3
spec:
ipRanges:
- start: 10.102.40.41
end: 10.102.40.51
# - cidr: 10.102.40.0/24
nodeSelector: {}
# matchLabels:
# egress-l3: antrea-egress-l3
And the Egress:
apiVersion: crd.antrea.io/v1alpha2
kind: Egress
metadata:
name: antrea-egress-l3
spec:
appliedTo:
podSelector:
matchLabels:
app: ubuntu-20-04
externalIPPool: antrea-ippool-l3
Apply it and check the IP address from the POD….
Well, how about that?
I know my workers reside on these ip addresses, but my POD is using a completely different IP address:
andreasm@linuxvm01:~/antrea/egress/deploy-frr$ k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-qn52t Ready <none> 21h v1.23.8+vmware.2 10.102.6.16 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-wmj7z Ready <none> 21h v1.23.8+vmware.2 10.102.6.17 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-node-pool-01-5hz5z-5597d8895f-z7cds Ready <none> 21h v1.23.8+vmware.2 10.102.6.15 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
wdc-2-tkc-cluster-1-xrj44-qq24c Ready control-plane,master 21h v1.23.8+vmware.2 10.102.6.14 <none> Ubuntu 20.04.5 LTS 5.4.0-128-generic containerd://1.6.6
What about the routing table in my upstream bgp router:
*> 10.102.40.41/32 10.102.6.17 0 0 66889 ?
Well have you seen..
Objective accomplished—->